记录一次 GPU 推理与管理服务的网络优化实践。企业在使用 GPU 服务器进行大模型训练与推理过程中,发现通过…
一、背景
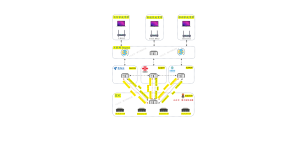
企业租用了一些 GPU 服务器,进行大模型微调训练。训练节点使用 NVIDIA GPU,操作系统为 Ubuntu,训练框架为 PyTorch,模型权重已部署在本地存储中。
实际业务运行中,GPU 服务器除了离线训练,还需要对外提供推理接口、Web 管理界面以及 API 服务,用于系统调用、测试验证和成果交付。这类服务以 HTTP/HTTPS 方式对外开放,需要网络质量稳定。
二、问题现象
实际使用中,GPU 服务器需要对外提供用于提交训练任务和查看运行状态的 Web 控制台、供内部系统或合作方调用的推理 API,以及前端页面、管理后台对外访问资源。在测试和交付阶段,还需要通过公网直接访问 GPU 服务节点进行功能验证。
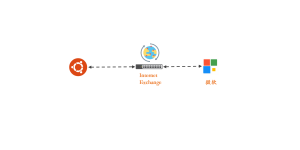
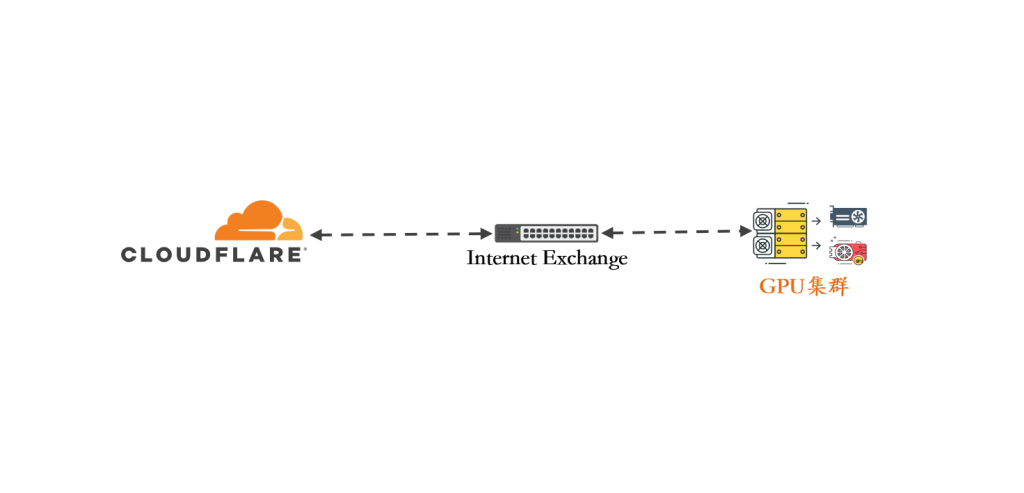
在这个项目中,Cloudflare 作为 GPU 推理服务和管理后台的公网入口,承载 API 与 Web 服务的对外访问流量,并提供 TLS、HTTP/2 及连接复用等网络层能力。
GPU 节点需要持续提供稳定的公网访问能力。实际运行中发现,通过运营商默认公网链路访问 GPU 服务时,访问路径由上游网络决定,存在绕行和链路变化情况,不同时间段和不同访问区域的连接表现存在明显差异,直接影响推理接口的可用性和响应稳定性,表现为接口超时、连接中断或响应波动,影响业务验证和交付过程。
基于上述情况,在现有网络结构不变的情况下,通过 Internet Exchange(IX)与 Cloudflare 建立 BGP 对等关系,使访问 Cloudflare 的路径直接进入对等网络。
三、对等互联政策
确认需求和访问来源之后,查阅 Cloudflare 官方的对等互联政策:

大意就是Cloudflare 支持通过 Internet Exchange(IX)进行 Public Peering,提供自助化接入流程。BGP 对等建立通过 Cloudflare Peering Portal 完成,直接使用 PeeringDB 账号进行 OIDC 授权登录。登录后,系统自动读取 PeeringDB 中登记的 ASN、对等位置及网络信息。
四、部署过程
4.1 登录Cloudflare平台
登录这个Cloudflare Peering Portal,使用自己的Peeringdb账号进行登录授权。
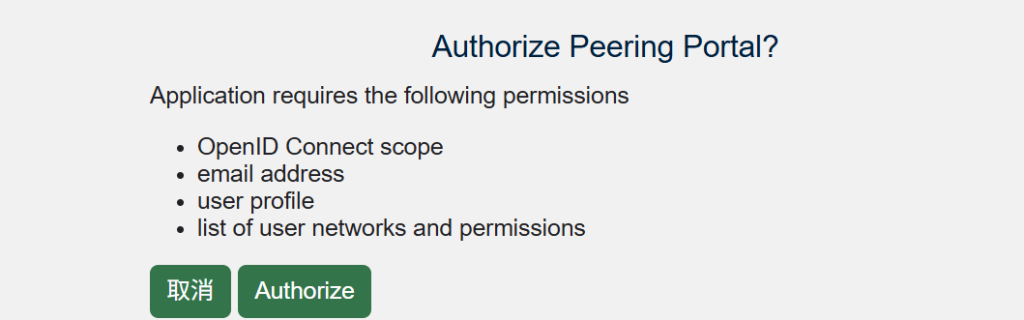
4.2 请求连接
登录完成授权后,CF会自动同步 PeeringDB 中的信息,我看有ASN、对等地点、联系方式及IP前缀。
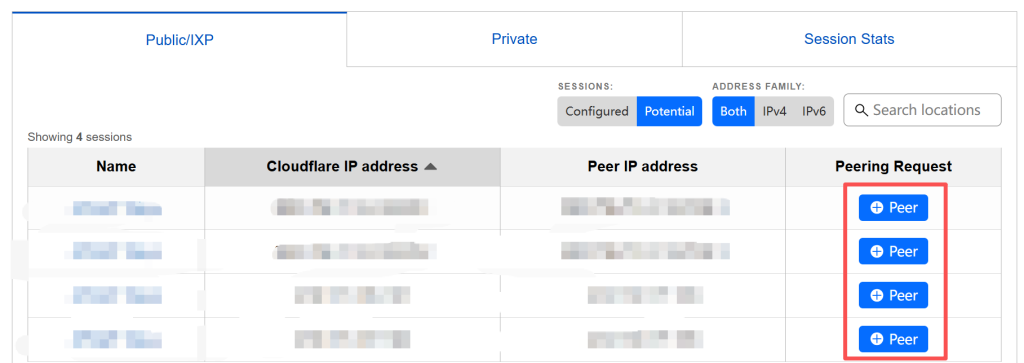
4.3 发起 BGP 对等请求
选择对应的IX节点,填写 BGP 密码并提交申请,请求进入 Cloudflare 的自动化审核流程,等待对等关系建立。
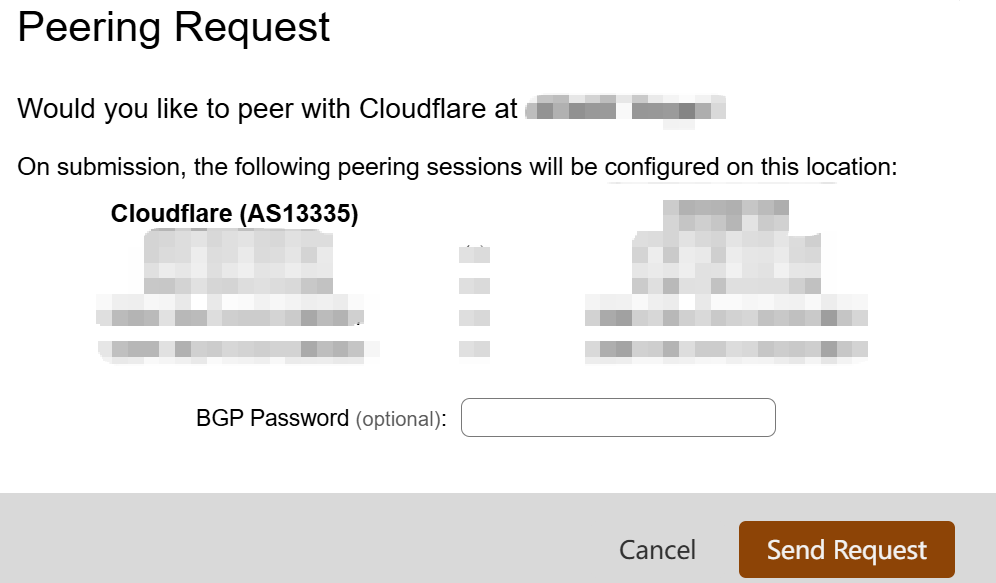
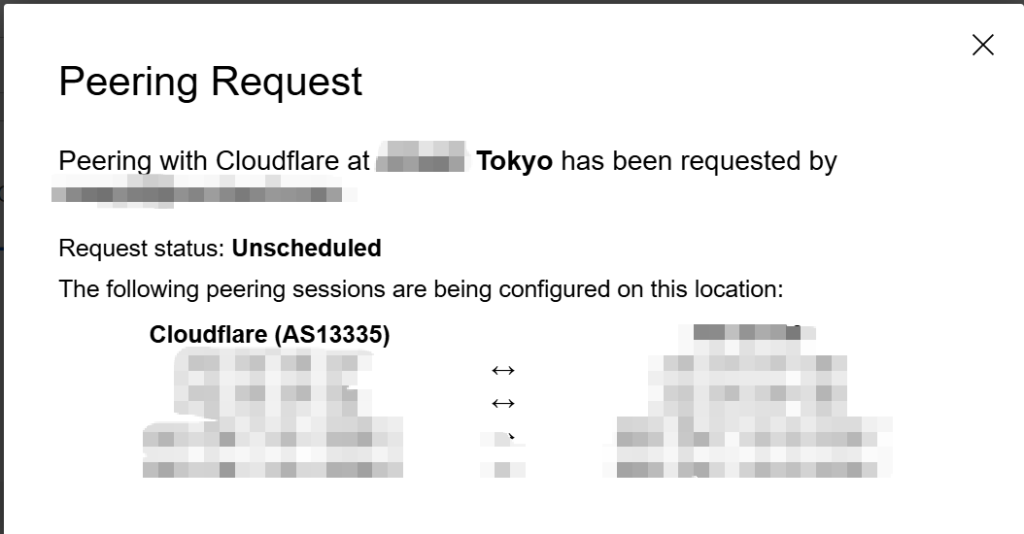
4.4 BGP建立成功
我等了大概6-8小时左右,睡了一觉,BGP状态就正常了,总共ipv4的路由7004条,ipv6的路由大概461条。
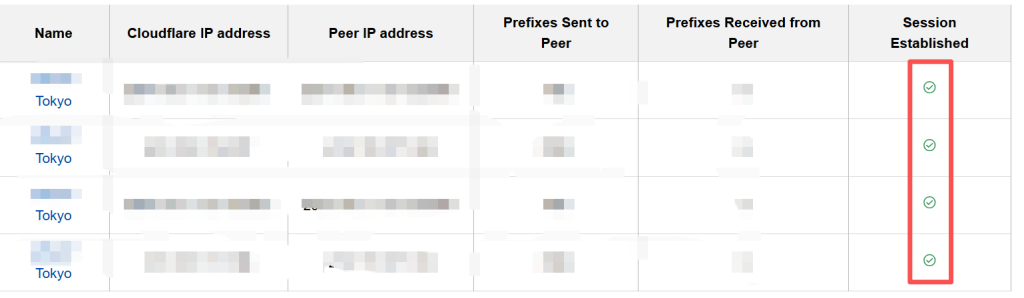


五、业务测试
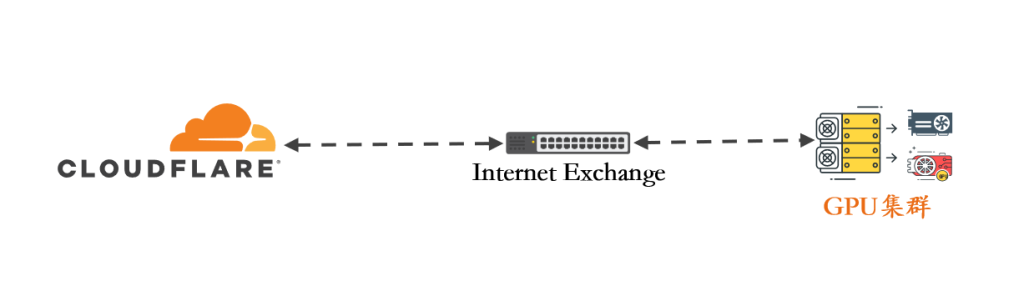
由于 GPU 推理与模型服务属于客户生产业务,直接对客户业务接口进行公网测试,会暴露客户业务访问特征,本次不对客户真实业务流量进行直接测试。
测试环境未暴露实际业务域名,不能使用基于域名的 Trace 接口进行验证,而是通过 BGP 路由表、IX 侧 Looking Glass 以及 Cloudflare 官方测速工具综合确认访问路径进入 Cloudflare 网络。
5.1 Cloudflare 官方测速工具
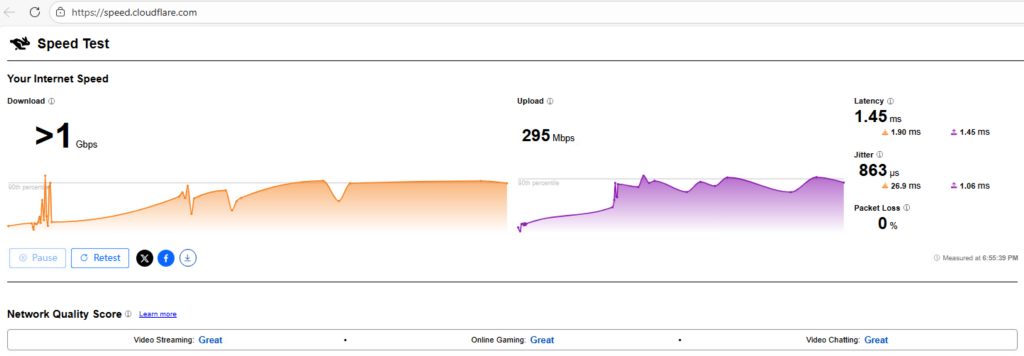
使用 Cloudflare 官方测速工具(speed.cloudflare.com),验证访问 Cloudflare 节点的实际 RTT、吞吐能力与稳定性;
延迟(Latency):基础 RTT:1.45 ms;
抖动(Jitter):基础抖动:863 μs。
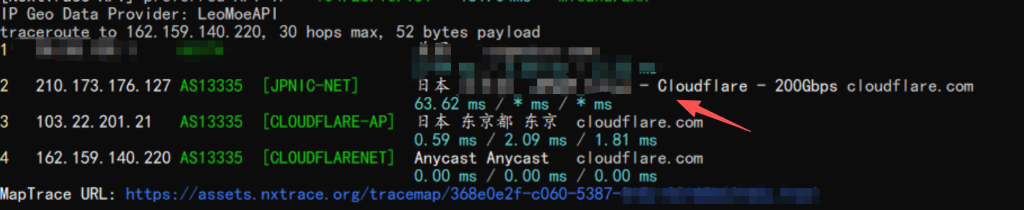
5.2 路由路径验证
一跳就进去了,第一跳是我自己的公网IP,打了个码。
六、结果汇总
通过本次 IX 直连 Cloudflare 的实践,对 GPU 推理服务的公网访问路径进行了对比。结果显示,在相同算力和服务配置条件下,不同公网路径对访问稳定性和响应表现存在影响。
通过直连 Cloudflare,可以在不增加复杂应用改造、不暴露业务细节的情况下,提升 GPU 推理服务的公网访问稳定性,为后续规模化部署和业务扩展提供更可控的网络基础。
基于真实环境(扩展)整理,如需进一步沟通相关需求,可通过页面右侧方式与我联系。