最近在一个北京到深圳的长途专线项目中,客户频繁反馈远程桌面卡顿,但网络监控、BGP、接口状态全部正常。经过长时…
感觉网络卡,但所有监控都正常
最近遇到一个很典型的长途专线丢包问题。客户在北京和深圳之间有大量远程桌面办公业务,员工每天都需要通过专线访问深圳机房里的办公系统。
客户反馈最明显的问题就是:远程桌面会偶发卡顿。有时候鼠标突然不动,过几秒又恢复;有时候键盘输入会延迟;严重时甚至会短暂黑屏一下,但连接又不会真正断开。
奇怪的是,整个网络看起来完全正常:
- BGP 没掉
- 接口没 Down
- 带宽没跑满
- 监控图表也没有异常
但连续观察后发现,链路确实存在丢包。只是这个丢包非常“诡异”。
丢包不是持续性的,而是每隔几个小时,随机丢 3~5 个包,然后又恢复正常。
正常情况下,企业级长途专线即使连续测试 100 万个数据包,也不应该出现明显随机丢包。
这种问题对网页访问影响可能不明显,但对远程桌面、视频会议、TCP 长连接业务影响非常大。尤其是 RDP 远程桌面,对瞬时丢包非常敏感。
更麻烦的是,这种随机丢包问题很难和线路维护方沟通。因为从监控角度看,线路大部分时间又是“正常”的。
但问题在于,客户的远程桌面业务确实在卡。
用户不会关心你 BGP 有没有掉,他们只知道:
“鼠标卡住了。”
“输入延迟了。”
“远程桌面又顿了一下。”
而这种偶发性小丢包,恰恰是最难解释、最难证明、也最容易被施工方忽略的问题。
长时间测试结果
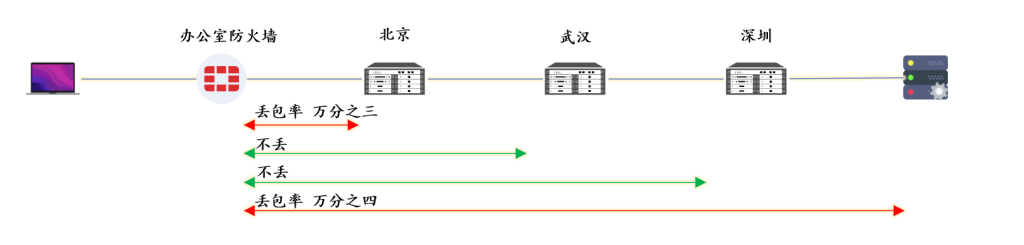
第一次测试,10000 个数据包,每0.1秒 发一个,测试结果如下:
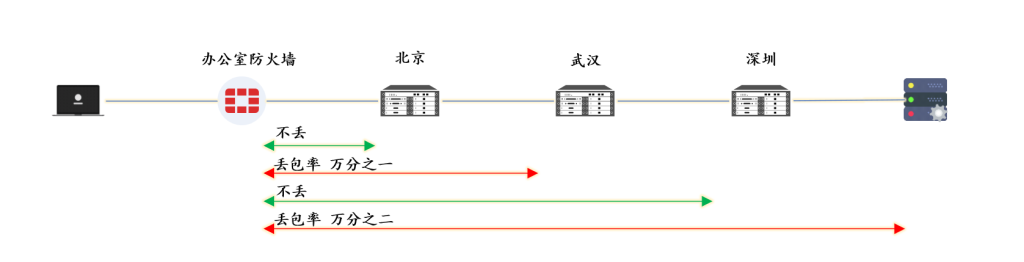
第二次测试,10000 个数据包,每0.1秒 发一个,测试结果如下:
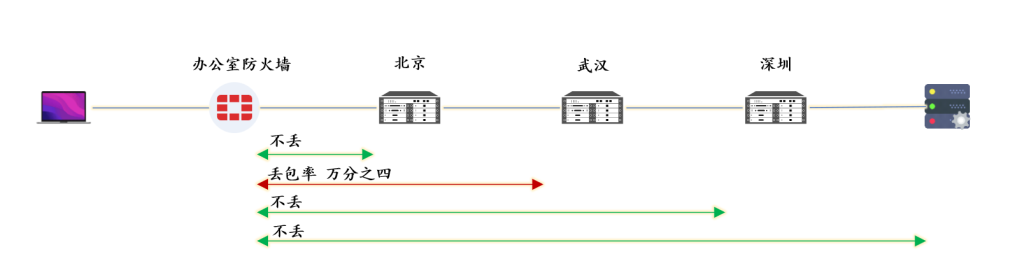
第三次测试,10000 个数据包,每0.1秒 发一个,测试结果如下:
最麻烦的是,这种问题并不是稳定复现的。有时候连续 10 万个包完全正常,但客户远程桌面还是会偶发卡顿。
排查思路
后来决定不再继续依赖 Ping 排查,因为这种随机丢包场景,Ping 很难真正定位问题。
普通监控抓不到,那就直接统计每一段链路到底收了多少包、发了多少包。
采用的是华为 Traffic Policy 的流量统计功能。
分别在北京专线、中间汇聚节点以及深圳网络专线出口部署了统计策略,通过 ACL 只匹配客户业务1.1.1.1的流量。
配置这样:
acl number 3010
rule 5 permit ip 1.1.1.1 0
#
traffic classifier in-c1 operator or
if-match acl 3010 precedence 5
#
traffic behavior in-b1
#
traffic policy in-p1
statistics enable
classifier in-c1 behavior in-b1然后通过 traffic policy 统计流量:
display traffic policy statistics interface GigabitEthernet0/0/5 inboundTraffic policy applied at 2026-05-09 13:20:45
Statistics enabled at 2026-05-09 13:20:45
Statistics last cleared: Never
Rule number: 1 IPv4, 0 IPv6
Current status: OK!
Item Packets Bytes
-------------------------------------------------------------------
Matched 10,000 108,736
+--Passed 10,000 108,736
+--Dropped 0 0
Missed 0 0
Last 30 seconds rate
Item pps bps
-------------------------------------------------------------------
Matched 0 0
+--Passed 0 0
+--Dropped 0 0
Missed 0 0接下来就是从源地址ping 10万到目的地址1.1.1.1的IP报文,然后总结数据。
问题定位
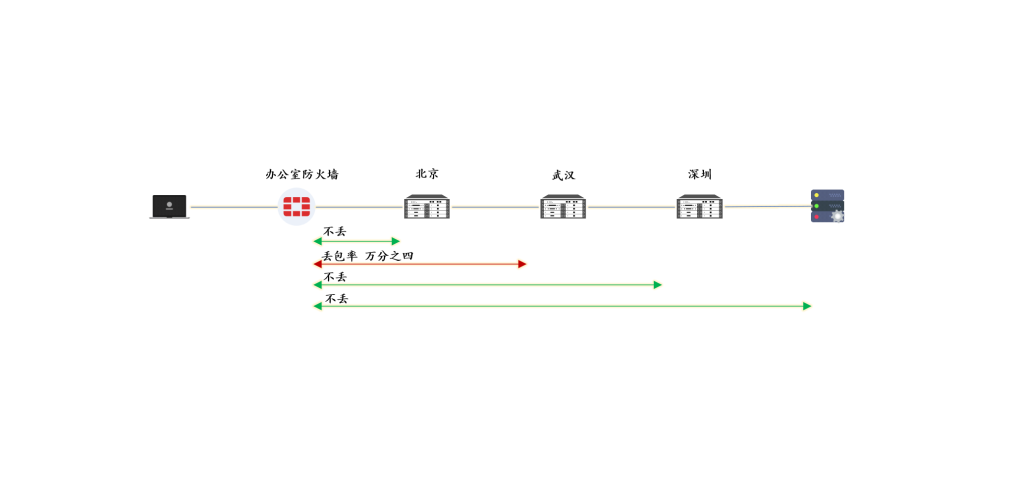
从最末端链路开始统计和清点,数据始终一致,收多少、发多少完全对得上。
但在最后一段OTN传输附近,开始出现差异。
- 客户侧发出来100000个包
- OTN最近的交换机只有 99995 个包
丢包就在最后一节链路,属于隐性的丢包场景。
主要原因是光纤质量问题、网线问题、SFP模块问题、接口问题。
这种问题最麻烦的地方就在于:它不会让链路直接断。所以传统监控很容易误判“网络正常”。
最终处理方案
业务侧根本不可能给你慢慢排查的试错时间,只能一次性解决问题。
- 更换光模块
- 更换尾纤
- 清洁光纤接口
- 换接入端口
- 换6类网线
处理完成后继续观察,随机丢包彻底消失。
Traffic Policy 的收发统计也恢复一致,客户侧业务恢复正常。
总结一下
很多长途传输的问题,并不是彻底中断,而是链路进入一种“亚健康状态”。
- 光模块老化
- 尾纤接触不良
- 波分轻微抖动
- 某段传输质量下降
这些问题不会让链路直接 Down,但会造成轻微随机丢包。
而这种小丢包,对视频会议、TCP 长连接、数据库同步影响反而非常明显。
很多长途专线问题,并不是链路彻底中断,而是网络进入一种“亚健康状态”。
这种问题最难处理的地方在于:从监控角度看,它不算严重故障;但从业务体验角度看,客户又能真实感知到卡顿。
基于真实环境(扩展)整理,如需进一步沟通相关需求,可通过页面右侧方式与我联系。